如果你的网站网页重复或者相似页面过多将会影响你网站的排名,那么如何计算网站内网页的相似度分布?
本文教你通过开发Python脚本使用TF-IDF算法计算网站全站页面相似度分布并可视化展示出来。
0. TF-IDF
TF-IDF(英语:term frequency–inverse document frequency)是一种用于信息检索与文本挖掘的常用加权技术。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级。除了TF-IDF以外,互联网上的搜索引擎还会使用基于链接分析的评级方法,以确定文件在搜索结果中出现的顺序。1
1. 计算原理
通过sitemap获取全站公开url,使用chrome无头浏览器抓取每个页面截图及其html源文件,然后抽取html中的可视文本,拿到每个页面文本后将页面内容分词后抽象为一个向量,互相计算每个页面向量之间的相似度(夹角),使用的算法为TF-IDF算法,如下:
假设现在有一个包含 1000 个文档的文档集合,其中包括文档:[经济,发展,新常态,研究,……],该文档总词汇数是 100,“经济”这个词汇出现了 4 次,则“经济”一词的词频(TF)为 4/100 = 0.04,如果在 1000 个文档中有 100 个文档出现过“经济”一词,则逆向文档频率(IDF)为 log(1000/100) = 1,那么在 TF-IDF 矩阵中,该文档中“经济”一词对应的权数应为 0.04*1=0.04。

2. 计算代码

点击图片查看源代码
3. 计算结果
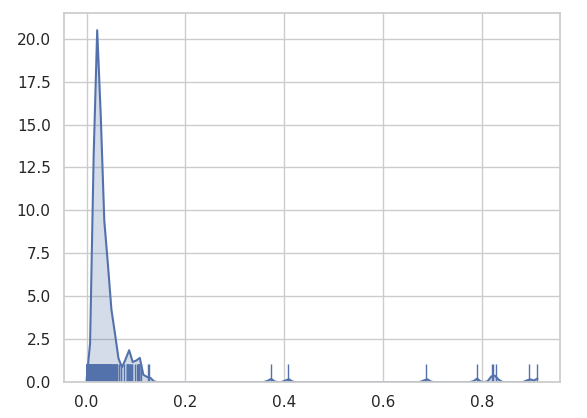
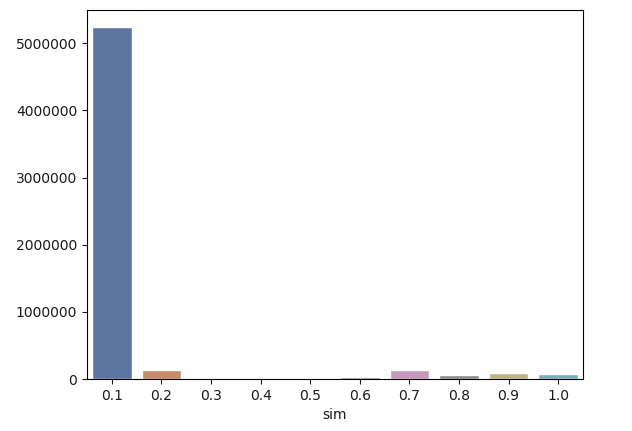

从上图可以看出全站相似度并不高,大部分页面相似分布在10%-20%之间,处于可接受范围。如果相似页面多,则热力图可能会出现如下情况:
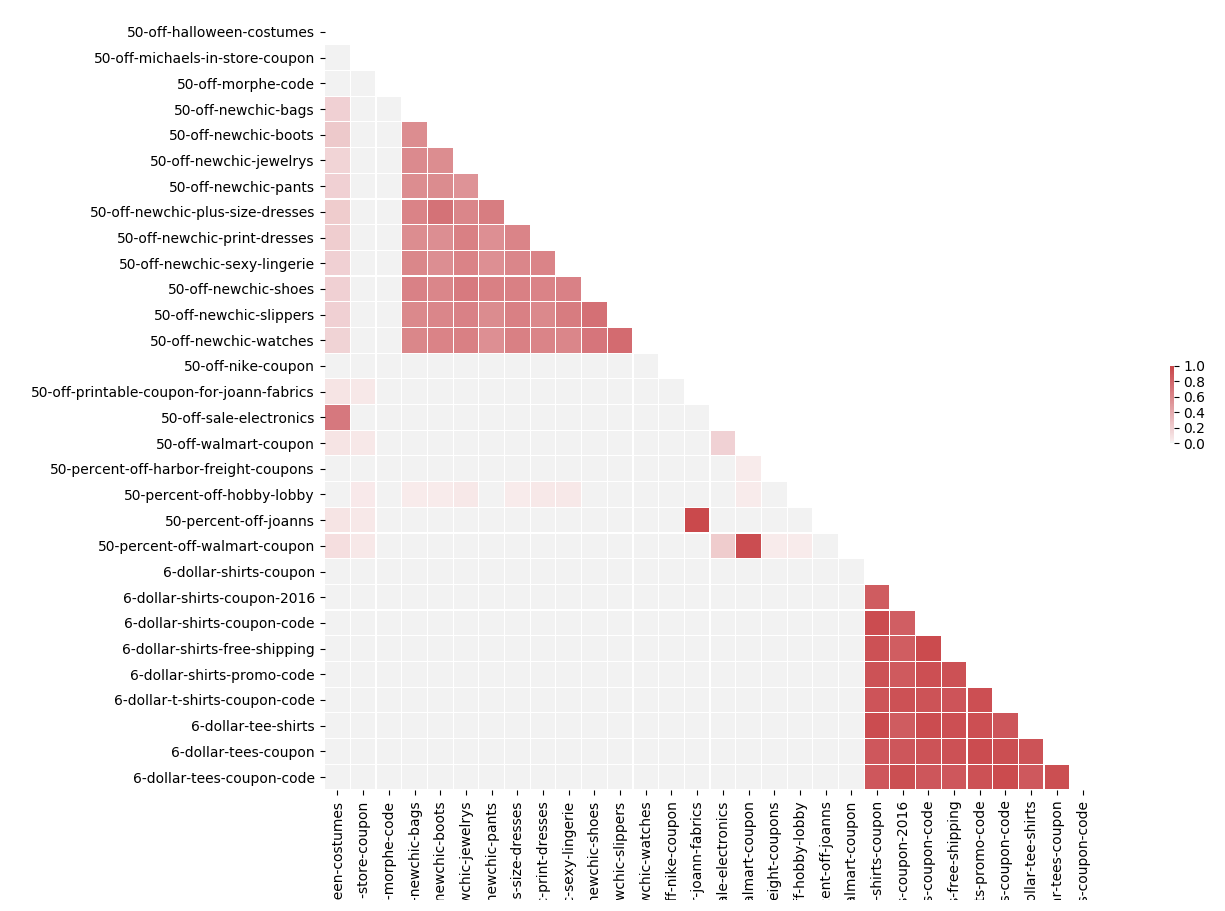
红色区域表示这些相关页面相似度极高。