从操作系统运行程序说起
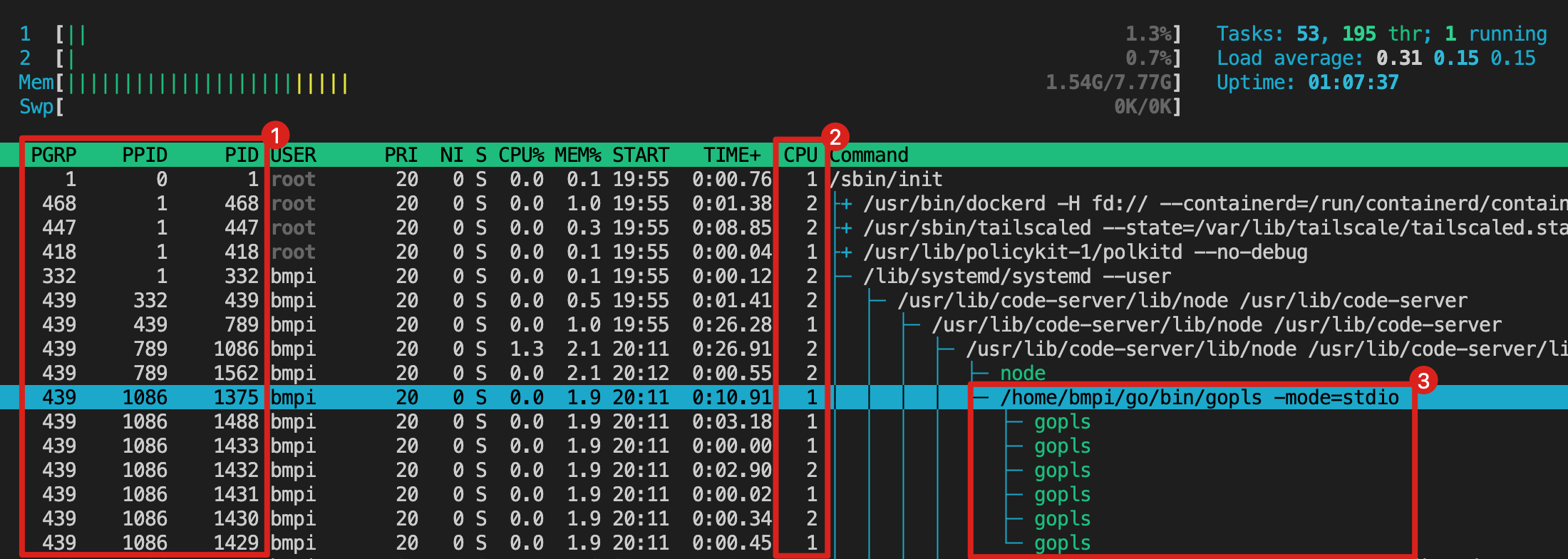
这是一台拥有2个虚拟CPU核心的Linux服务器的系统监控界面。其中红框①中PPID代表父进程ID,PID代表进程或线程ID。红框②中CPU代表当前线程运行的CPU核心编号。红框③中是程序的运行命令,其中绿色代表的是线程,白色为进程。
以PID为1375的进程为例,它的父进程为1086,可以通过PPID不断追溯至PID为1的init进程。从这可以看出Linux通过fork()的系统调用不断的复制出大量的需要被执行的程序进程。
进程是操作系统进行资源分配的一个独立单位,而实际在CPU运行调度的是线程。以进程1375为例,它又创建了7个线程,如下:
$ ls /proc/1375/task/
1375 1429 1430 1431 1432 1433 1488
$ ls /proc/1375/task/1429
arch_status cgroup cmdline cpuset exe gid_map loginuid mountinfo ns oom_score patch_state root sessionid smaps_rollup statm uid_map
attr children comm cwd fd io maps mounts numa_maps oom_score_adj personality sched setgroups stack status wchan
auxv clear_refs cpu_resctrl_groups environ fdinfo limits mem net oom_adj pagemap projid_map schedstat smaps stat syscall
其中线程1430与1432是调度运行在2号CPU核心上的,如果持续观察这个监控界面,会发现同一个线程会不定时在两个CPU核心之间来回切换,这实际正是操作系统对这些线程在多核CPU上进行抢占式调度。
操作系统之所以能用有限的CPU核心去运行非常多的程序,并且用户感觉这些程序是在同时运行。一方面操作系统(内核)可以通过一些方法实现并发处理任务(程序),另外一方面得益于多个CPU核心,操作系统还可以并行处理任务。
本文并不是研究操作系统是怎么实现并发的,但在搞清楚编程语言是怎么实现并发处理之前,很有必要提前对操作系统支持并发提供的一些重要特性做一个全面的介绍。操作系统为了支持多任务处理,提供了进程管理与调度,同时在I/O上提供了多种访问文件或网络的系统调用方式。
操作系统的支持
# 操作系统
## 进程(Process)
### 调度方式
- 抢占式(Preemptive)
- 协作式(Cooperative)
### 执行方式
- 用户线程(User-level Thread)
- Coroutine
- Verticle
- Goroutine
- Erlang process
- Green Thread(Java)
- 内核线程(Kernel-level Thread)
- 纤程(Fiber)
## I/O
- 同步(Synchronous)
- 阻塞式(Blocking)
- 非阻塞式(Non-blocking)
- 多路复用(Multiplexing)
- 信号驱动(Signal Driven)
- 异步(Asynchronous)
调度(Scheduling)
进程调度主要有抢占式调度和协作式调度两种:抢占式(Preemptive)与协作式(Cooperative)。

抢占式与协作式任务调度(Preemptive Multitasking vs. Cooperative Multitasking)
抢占式调度往往在一些重要位置(Sleep Call,Timer Tick)放置了中断信号,通过这个信号通知操作系统调度器(Scheduler)进行进程切换。在抢占式模型中,正在运行的进程可能会被强行挂起,这是由于这些中断信号引发的。
协作式调度也叫非抢占式调度,是指当前运行的进程通过自身代码逻辑出让CPU控制权。与抢占式调度的区别在于进程运行不会被中断信号打断,除非其主动出让控制权给其他进程。
以上描述并没有明确区分进程还是线程,实际在Linux系统的内核态上,用户态的线程统一按轻量级进程(Light-weight process)来处理,它们与真正的进程的区别是在一个用户态进程中的线程共享了相同的地址空间和其他资源(如打开的文件描述符),但在内核调度上并没有什么区别。
线程是进程的运行实例,哪怕在非多线程的进程中,在内核态实际运行进程的还是内核线程,所以接下来介绍下线程的分类。
线程(Thread)
我们在编程语言中见到的线程,一般指的是与内核线程一一映射的用户态线程,比如Java中的Thread其实就是内核线程。但一些编程语言如Erlang与Go都实现了更轻量级的用户线程。
- 用户线程(User-level Thread)
- 协程(Coroutines - Cooperative User-Level Threads):应用程序通过线程库自行实现的协作式调度的用户线程,代表性的有Go语言的Goroutine(1.14之前的版本),Vert.x框架中的Verticle。
- Go Goroutine:Go语言的Goroutine在1.14之前是协程的机制,之后的版本采用了异步抢占式调度(asynchronously preemptible)。
- Erlang process:Erlang VM(BEAM)管理的用户线程,与协程相比的优势在于它可以做到公平调度,不会出现协程中某个用户线程占用过多CPU周期。
- 绿色线程(Green Thread):类似于协程,是由Java JDK实现的,但因为早期Linux系统没实现内核态的抢占式调度,Green Thread只能在Solaris系统上发挥它的威力,最终在JDK 1.3之后被Native Thread取代。所以现行的JDK的线程实际是非常重量级的内核态线程,Java的Project Loom会尝试实现新的Green Thread方案,并且是抢占式的调度方案。
- 内核线程(Kernel-level Thread):操作系统内核管理的抢占式调度的线程,是最终运行在CPU上实际执行任务的最小单元。
- 纤程(Fibers):操作系统内核管理的协作式调度的线程。这一系统级别的方案最终因硬件和软件的发展逐渐式微,现在的用户线程也能达到协作式调度的效果。
用户线程与内核线程的区别在于用户线程的调度是发生在用户态,内核中无法感知到用户线程的存在,并且调度也发生在用户态,一般是由线程库或编程语言运行时自行实现的。而内核线程的调度是由内核完成的,一般是抢占式调度。
用户线程(User-level Thread)
用户线程大多是采用协作调度的方式实现,本质上是同步执行在与CPU核心数量相同的内核线程上的,不仅能极大的降低了上下文开销,还能最佳的利用多核CPU的计算能力。
用户线程的轻量除了体现在调度的上下文切换开销上,还体现了在对内存的需求上。如果要在4核心4GB内存的笔记本电脑中测试同时生成100万个线程的话,不同编程语言对内存的需求:
- Elixir: 0.48 GB (Process)
- Golang: 1.91 GB (Goroutine)
- Java: 977 GB (Thread)
- PHP: 6836 GB (Laravel Request)
数据来源:Programming ElixirChapter 15
但用户线程的执行最终是由内核线程来完成,所以存在一个从用户线程到内核线程的映射模型。
线程模型(Thread Model)
可能有人会疑惑,用户线程与内核线程是一一映射的吗?总的来说有以下三种线程模型:

不同的线程模型(Different Threading Models)
- 1x1 (kernel-level threading):用户线程与内核线程是一一映射的。这是最简单的模型。在这种语境下,用户线程中的线程就是我们常规意义上说的线程,当程序创建一个线程时,也会在内核中创建一个内核线程。目前大多数操作系统如Linux、Solaris、FreeBSD、macOS与iOS内核的线程模型就是这种。
- Nx1 (user-level threading):多个用户线程与一个内核线程映射。在这种模型中,内核线程只有一个,在应用内部不存在内核线程切换的开销,程序的并发能力是很高的。但一旦某个用户线程被阻塞(发生网络或文件I/O系统调用),其他用户线程也会被阻塞。另外应用也无法从多核CPU上获得更好的并发性。所以实际的使用场景中,这种模型并不常见。
- MxN (hybrid threading):多个用户线程与多个内核线程映射。这种模型最为复杂,但也是最强大的线程模型,不仅有着很好的并发能力,同时还能获得多核CPU的处理能力。早期的Solaris内核中也支持这种线程模型,但因为其会导致内核调度过于复杂,逐渐被放弃。但在Erlang VM和Go语言的运行时就又实现了这种线程模型。

早期Solaris内核的线程和轻量级进程(Threads and Lightweight Processes)
轻量级进程(Light-weight process):Solaris内核中的概念,但也会在其他系统内核中看到类似的概念。指的是用户线程和内核线程之间的接口,也可被认为是一个调度用户线程执行的虚拟CPU。当用户线程发出系统调用时,运行该线程的LWP调用内核并保持绑定到该内核线程至少直到系统调用完成。当LWP在内核中为用户线程执行系统调用时,它会运行一个内核线程。因此,每个LWP都与一个内核线程相关联。只有在用户线程完全由轻量级进程构成时,才可以说轻量级进程就是线程。Go语言中Goroutine的G-P-M调度模型中,P承担了类似LWP的角色。
应用程序为什么会费劲的设计出用户线程?操作系统提供的内核线程不香吗?这是因为操作系统内核的线程切换是重量级的操作,它需要进行上下文切换,而这会很耗时。
上下文切换(Context switching)
在进程间切换需要消耗一定的CPU时钟周期进行相关的状态管理工作,包括寄存器和内存映射的保存与读取、更新各种内部的表等。比如在Linux内核中,上下文切换需要涉及寄存器、栈指针、程序计数器的切换。
在这篇How long does it take to make a context switch?中可以看到一个结论是:
Context switching is expensive. My rule of thumb is that it’ll cost you about 30µs of CPU overhead…Applications that create too many threads that are constantly fighting for CPU time (such as Apache’s HTTPd or many Java applications) can waste considerable amounts of CPU cycles just to switch back and forth between different threads…I think the sweet spot for optimal CPU use is to have the same number of worker threads as there are hardware threads, and write code in an asynchronous / non-blocking fashion.
因为线程调度的上下文切换成本非常昂贵,所以最佳的做法是应用程序使用和CPU核心相同的线程数,这样每个线程都能充分利用CPU核心的时间片,避免了应用内部多个线程的上下文切换开销。
用户线程的轻量级让应用程序能够极大的提高并发性,但也会有一些问题,比如某个用户线程中发起一个网络请求导致底层的内核线程被阻塞,因为多个用户线程在共用这个内核线程,最终导致大量的用户线程被阻塞。
解决这个问题需要了解操作系统的I/O模型。
I/O模型(I/O Model)
当应用程序需要访问文件或者网络资源时,应用内的线程将会花费大量的时间来等待数据的到来。如下图所示:
如果把CPU处理计算机指令的速度类比成高铁的速度,那线程一次文件或网络的访问将会和蜗牛一样慢,这相当于你在高铁上让蜗牛去帮你取快递,对CPU来说是巨大的浪费。现代操作系统已经提供了多种I/O模型来解决这个问题。常见的I/O模型有:

五种I/O模型对比(Comparison of the five I/O models)
- 同步(Synchronous)
- 阻塞式(Blocking):同步阻塞式是最常见的I/O模型。线程在访问文件或网络资源时,会因发起了内核的系统调用被挂起,内核会检查文件描述符是否可读,当文件描述符中存在数据时,内核会将数据复制给线程并交回控制权,线程从挂起状态切换成可运行状态等到内核调度运行。
- 非阻塞式(Non-blocking):线程在访问文件或网络资源时,因文件描述符是非阻塞的,线程在检查数据是否可读的阶段是非阻塞的。此模型需要线程不停的通过轮询(polling)的方式检查文件描述符是否可读。但之所以属于同步I/O,是因为在最终读取数据(
recvfrom)时需要从内核态中拷贝数据(recvfrom)到用户态中,这个阶段线程依旧被阻塞住无法处理其他指令。 - 多路复用(Multiplexing):和非阻塞式的区别在于,多路复用模型的线程可以同时访问多个文件描述符,这很适合构建高并发的Web服务器或中间件。但此模型会在检查文件描述符时会被阻塞(
select),并且在读取数据(recvfrom)时也会被阻塞。和多路复用模型相似的是使用多线程和阻塞I/O,但当线程产生很多时会消耗大量的内存资源以及线程调度产生的上下文切换开销,所以多路复用模型一般只使用单线程模型。 - 信号驱动(Signal Driven):和上面的模型区别在于,之前的模型都需要线程主动轮询,信号驱动模型需要监听内核的
SIGIO事件,通过注册事件处理函数,之后线程可以继续执行其他任务。当数据可读时,线程处理函数会以阻塞的方式从内核态复制数据到用户态。
- 异步(Asynchronous):此模型和同步模型最大的区别在于,不仅在获取文件操作符时不会被阻塞,数据从内核态复制到用户态也不会被阻塞,因为内核会去做这个复制数据的工作,线程只需要在回调函数中使用数据即可。
关于I/O模型的更多细节,请参考:
思考一个问题:如果用户线程不可避免的需要被挂起进(如访问共享资源但没有获得锁)而导致内核线程被挂起,如何调度可以让此内核线程上的用户线程可以继续运行?
并发还是并行
前面讨论了很多和I/O相关的概念,并不是所有的计算机任务都是和I/O相关(I/O bound)的,比如很多算法都需要CPU做大量的计算,这时候CPU核心根本不会因为等待外部资源而空转,如果在这种计算密集型(CPU bound)任务中使用多线程技术,那么就会产生大量的线程上下文切换开销,最终会导致处理任务的性能变慢。
在这篇Scheduling In Go : Part III - Concurrency文章中,作者对比了两种类型工作在并发和并行模式的对比,并提供了一些经验总结:
- CPU密集型(CPU bound):如果任务是CPU密集型的,那么使用并行的方式来解决问题,这样可以最大的利用CPU核心的算力。如果使用并发的方式去处理,反而会增加复杂度。
- I/O密集型(I/O bound):如果任务时I/O密集型的,那么使用并发的方式来解决问题,这样可以提升单个CPU核心的吞吐量(Throughput)。
并发(Concurrent)与并行(Parallel):并发是指同时处理(dealing with)很多事情,并行是指同时做(doing)很多事情。并行是并发的特殊情况,只能在计算机多核环境中实现。
同步(Sync)与异步(Async):一种编程模型。区别在于同步是可预测(predictable)的,异步是不可预测(unpredictable)的编程模型。
总结
本篇从操作系统的视角介绍编程语言实现并发的底层概念,包括进程调度与I/O模型等。下篇开始介绍常见的并发模型。